RNN
RNN框架图
梯度消失及爆炸
Todo
LSTM
从RNN网络出发开始介绍LSTM网络,记录其架构图及公式。
LSTM的框架图
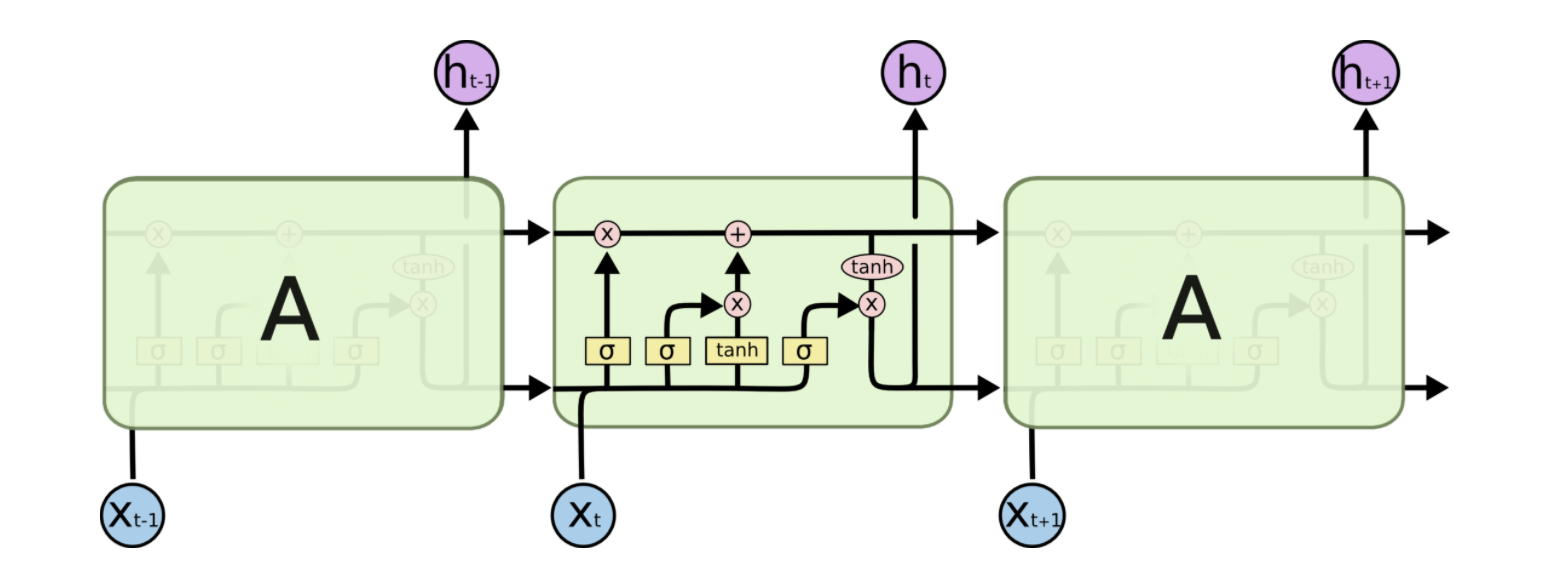
遗忘门
输入门
输出门
梯度问题
- 首先需要明确的是,RNN 中的梯度消失/梯度爆炸和普通的 MLP 或者深层 CNN 中梯度消失/梯度爆炸的含义不一样。MLP/CNN 中不同的层有不同的参数,各是各的梯度;而 RNN 中同样的权重在各个时间步共享,最终的梯度 g = 各个时间步的梯度 g_t 的和。
- RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
- LSTM 中梯度的传播有很多条路径,cell 这条路径上只有逐元素相乘和相加的操作,梯度流最稳定;但是其他路径上梯度流与普通 RNN 类似,照样会发生相同的权重矩阵反复连乘。
- 但是在其他路径上,LSTM 的梯度流和普通 RNN 没有太大区别,依然会爆炸或者消失。由于总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径(就是上面说的那条高速公路)梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度 = 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度。
- 同样,因为总的远距离梯度 = 各条路径的远距离梯度之和,高速公路上梯度流比较稳定,但其他路径上梯度有可能爆炸,此时总的远距离梯度 = 正常梯度 + 爆炸梯度 = 爆炸梯度,因此 LSTM 仍然有可能发生梯度爆炸。不过,由于 LSTM 的其他路径非常崎岖,和普通 RNN 相比多经过了很多次激活函数(导数都小于 1),因此 LSTM 发生梯度爆炸的频率要低得多。实践中梯度爆炸一般通过梯度裁剪来解决。
GRU
GRU框架图
公式
与LSTM区别
- GRU和LSTM的性能在很多任务上不分伯仲。
- GRU 参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
- 从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将 hidden state 传给下一个单元,而LSTM则用 memory cell 把 hidden state 包装起来。

