
TF-IDF及TextRank
1. TF-IDF
- TF
- TF是词频(TF,Term Frequency): 词频(TF)表示词条(关键字)在文本中出现的频率。
- IDF
- IDF是逆向文件频率 (IDF,Inverse Document Frequency): 某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
- TF-IDF
- TF-IDF实际上是 $TF * IDF$ 。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
2. TextRank
- 基于词语词之间的共现性构建无向图。
参考jieba源码分析之关键字提取(TF-IDF/TextRank)
激活函数
1.激活函数的理解
解决线形模型 y = wx + b 的弊端,线形分类模型的分界地方都是平面或者超平面,无法解决具有非线形模型特征的数据。如果没有激励函数,在这种情况下你每一层节点的输入都是上层输出的线性函数,无论你神经网络有多少层,输出都是输入的线性组合,相当于没有隐藏层,网络的学习能力有限。
形象的解释神经网络激活函数的作用是什么?
常见激活函数,及其优缺点 - 面试篇
2. Sigmoid
- 数学形式

- 导数形式

- 特点
- Sigmoid 函数的取值范围在 (0,1) 之间,单调连续,求导容易,一般用于二分类神经网络的输出层。特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
- 缺点
- 如果我们初始化神经网络的权值为 $[0,1]$ 之间的随机值,由反向传播算法的数学推导可知,梯度从后向前传播时,每传递一层梯度值都会减小为原来的0.25倍,如果神经网络隐层特别多,那么梯度在穿过多层后将变得非常小接近于0,即出现梯度消失现象;当网络权值初始化为 $(1,+∞)$ 区间内的值,则会出现梯度爆炸情况。梯度消失更容易产生。
- 其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
- Sigmoid 的 output 不是0均值(即zero-centered)。这是不可取的,这个特性会导致为在后面神经网络的高层处理中收到不是零中心的数据。这将导致梯度下降时的晃动,因为如果数据到了神经元永远时正数时,反向传播时权值w就会全为正数或者负数。
3. tanh
- 数学形式

- 导数形式

- 特点
- 解决了Sigmoid函数的不是zero-centered输出问题,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
4. Relu
- 数学形式

- 导数形式
- 优点
- 解决了梯度消失问题
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid
- 缺点
- 输出不是zero-centered
- 原点不可导
- Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见。例如w初始化全部为一些负数。 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
- leaky relu函数,$f(x)=max(αx,x)$ , 比如取α=0.01\alpha=0.01α=0.01,可以改善relu中x<0部分的dead问题。
5. 如何选择合适的激活函数
- 首选 ReLU,速度快,但是要注意学习速率的调整,
- 如果 ReLU 效果欠佳,尝试使用 Leaky ReLU 变种。
- 可以尝试使用 tanh。
- Sigmoid 和 tanh 在 RNN(LSTM、注意力机制等)结构中有所应用,作为门控或者概率值。其它情况下,减少 Sigmoid 的使用。
- 在浅层神经网络中,选择使用哪种激励函数影响不大。
逻辑回归(Logistic Regression)
1. 假说
假设样本的标签为0和1, $h(x)$ 为取得预测为标签1的概率。
其中, $ \delta(x)$ 为 $Sigmoid$ 函数
即:
线性变化 $f(x) = w^Tx $ 可以理解为一种回归,加入$Sigmoid$ 函数后值域为$[0,1]$,可以应用至分类分类问题,理解为逻辑回归。
2. 后验概率
3. 似然函数
N 为数据样本数
4. 对数似然
5. 损失函数
似然函数乘以 -1/N
6. 梯度下降
Loss 如下:
推导过程
参数更新如下:
参数更新理解
7. 实践
8. 一些问题
LR为什么是线性模型?
Logistic Regression从几率的概念构建线性回归模型。一个事件发生的几率(odds)为该事件发生的概率与不发生概率的比值,几率的取值范围为$[0,+\infty)$,其对数的取值范围为实数域,所以,可以将对数几率作为因变量构建线性回归模型: $log\frac{p}{1-p} = w^Tx$, 由此可得 $p = \frac{1}{1+e^{-w^Tx}}$。这便是Logistic Regression采用sigmoid函数的原因,sigmoid函数将自变量的线性组合映射到(0,1),用以表述分类的概率特性。从sigmoid函数看出,当$w^Tx >0 $ 时,y=1,否则 y=0。$w^Tx=0$ 是模型隐含的分类平面(在高维空间中,我们说是超平面), 所以说逻辑回归本质上是一个线性模型。为什么逻辑回归比线性回归要好?
逻辑回归能够用于分类,不过其本质还是线性回归。它仅在线性回归的基础上,在特征到结果的映射中加入了一层sigmoid函数(非线性)映射,即先把特征线性求和,然后使用sigmoid函数来预测。sigmoid函数
- 优点:
- Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
- 求导简单。
- 缺点:
- 由于其软饱和性,容易产生梯度消失,导致训练出现问题。
- 优点:
- LR 如何解决多分类问题?
如果y不是在[0,1]中取值,而是在K个类别中取值,这时问题就变为一个多分类问题。有两种方式可以出处理该类问题:一种是我们对每个类别训练一个二元分类器(One-vs-all),当K个类别不是互斥的时候,比如用户会购买哪种品类,这种方法是合适的。如果K个类别是互斥的,即 y=i 的时候意味着 y 不能取其他的值,比如用户的年龄段,这种情况下 Softmax 回归更合适一些。Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression), 模型通过 softmax 函数来对概率建模。
$probability$和$odds$的定义
- $probability$指的是发生的次数/总次数, 如果抛硬币:
$logit$函数和$sigmoid$函数及它们的特性
- 我们对$odds$取$log$, 扩展$odds$的取值范围到实数空间$[-\infty, +\infty]$, 这就是$logit$函数:
注意: 接下来我们会省略$log$的底$e$
- 接下来, 我们用线性回归模型来表示$logit(p)$, 因为线性回归模型和$logit$函数的输出有着同样的取值范围:
例如: $logit(p) = \theta_1 x_1 + \theta_2 x_2 + bias$
下面我们来画一下$logit(p)$, 注意$p \in (0, 1)$, 当$p=0$或$p=1$的时候, $logit$函数属于未定义.
参考
过拟合及其解决方法
1. 过拟合概念
在深度学习或机器学习过程中,在训练集上表现过于优越,在验证集及测试集中表现不佳,模型泛化能力差。
过拟合及常见处理办法整理
2. 常见原因
原因主要是数据样本少及噪声多
- 数据样本少
- 数据噪声多
- 模型复杂度高
- 迭代次数多
3. 解决方法
- 获取更多的数据
- 数据源获取更多的数据
- 数据增强
- 更改模型结构
- 换简单模型
- L1 & L2 范式
- Dropout
- Early Stopping
4. 数据增强
自然语言处理技术中常用的数据增强方法
- 同义词替换
- 随机插入
- 随机交换
- 随机删除
5. L1 & L2 范式
- 范式定义
- 加入范式的目标函数
- L1范式惩罚因子
- L2范式惩罚因子
- 结论
L1 正则化用作特征选择,L2 正则化用作防止过拟合
参考介绍—-机器学习中的正则化
6. Dropout
思想:以指数级别创建不同的网络结果,然后各个网络结果加权平均,解决过拟合
训练阶段,对每一个神经元的输出以keep_prob保留,1-keep_prob置为0;
预测阶段,对每一个神经元的输出乘以keep_prob。
缺点: 训练时间变长2-3倍。
参考介绍—-深度学习中Dropout原理解析
RNN、LSTM、GRU对比
RNN
RNN框架图
梯度消失及爆炸
Todo
LSTM
从RNN网络出发开始介绍LSTM网络,记录其架构图及公式。
LSTM的框架图
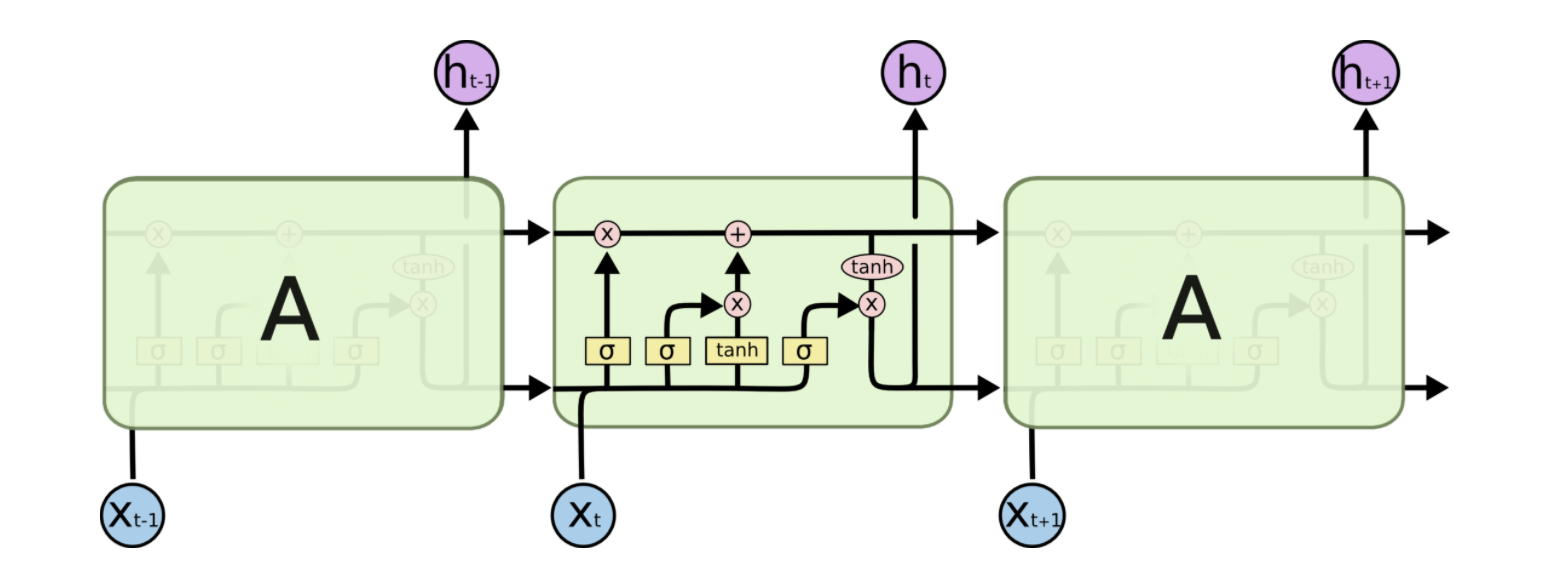
遗忘门
输入门
输出门
梯度问题
- 首先需要明确的是,RNN 中的梯度消失/梯度爆炸和普通的 MLP 或者深层 CNN 中梯度消失/梯度爆炸的含义不一样。MLP/CNN 中不同的层有不同的参数,各是各的梯度;而 RNN 中同样的权重在各个时间步共享,最终的梯度 g = 各个时间步的梯度 g_t 的和。
- RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
- LSTM 中梯度的传播有很多条路径,cell 这条路径上只有逐元素相乘和相加的操作,梯度流最稳定;但是其他路径上梯度流与普通 RNN 类似,照样会发生相同的权重矩阵反复连乘。
- 但是在其他路径上,LSTM 的梯度流和普通 RNN 没有太大区别,依然会爆炸或者消失。由于总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径(就是上面说的那条高速公路)梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度 = 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度。
- 同样,因为总的远距离梯度 = 各条路径的远距离梯度之和,高速公路上梯度流比较稳定,但其他路径上梯度有可能爆炸,此时总的远距离梯度 = 正常梯度 + 爆炸梯度 = 爆炸梯度,因此 LSTM 仍然有可能发生梯度爆炸。不过,由于 LSTM 的其他路径非常崎岖,和普通 RNN 相比多经过了很多次激活函数(导数都小于 1),因此 LSTM 发生梯度爆炸的频率要低得多。实践中梯度爆炸一般通过梯度裁剪来解决。
GRU
GRU框架图
公式
与LSTM区别
- GRU和LSTM的性能在很多任务上不分伯仲。
- GRU 参数更少因此更容易收敛,但是数据集很大的情况下,LSTM表达性能更好。
- 从结构上来说,GRU只有两个门(update和reset),LSTM有三个门(forget,input,output),GRU直接将 hidden state 传给下一个单元,而LSTM则用 memory cell 把 hidden state 包装起来。